小团队如何妙用 JuiceFS
15 年还在 ENJOY 的时候, 就已经在用 JuiceFS, 并且一路伴随着我工作过的四家小公司, 这玩意对我来说, 已经成了理所应当不可或缺的基础设施, 对于我服务过的小团队而言, 更是实实在在的好帮手. 趁着最近的征文活动, 继续拓展一下我的小团队系列, 介绍下多年来我们团队都在如何使用 jfs.
不过这里讲到的用途, 恐怕都不算什么”妙用”, jfs 是一个大社区了, 这些用法恐怕早被玩的滚瓜烂熟, 不过无妨, 本文其实是内部项目文档的拓展, 主要记录一些维护过程的心得体会.
妙用: 容器共享存储
虽然已经有了 CSI 支持, 但我们一直以来都将 Juicefs 挂载到所有 Kubernetes 节点的 /jfs, 这样一来, 所有容器应用都能轻松以 hostPath 方式来挂载宿主机目录, 然后就有了共享存储了. 此法的一些需要注意的地方:
jfs.mount必须先于容器服务启动, 毕竟二者建立依赖关系了. 以 docker 为例, 可以这么写:
# /etc/systemd/system/docker.service.d/12-after-jfs.conf
[Unit]
After=jfs.mount
- 要挂载的目录必须先手动创建出来, 设置好权限(使之与容器进程 uid 匹配), 这点其实不太方便, 如果你的团队受不了这番折腾, 就直接用 CSI 吧.
- 集群扩容存在一定不便之处, 毕竟此法要求所有节点都挂载好 jfs. 万一 Kubernetes 集群冗余不够了, 需要加入新节点, 还需要多做一步挂载 jfs, 才能加入集群. 在极限情况下, 这样的设计还挺耽误时间的, 又多了一个直接用 CSI 的理由.
讲了这么多问题, 那看上去确实应该首选 CSI 而不是 hostPath 了, 不过 hostPath 就胜在管理更简单, 推理更加直白, 因为依照我们的使用惯例, 都会采用类似 /jfs/[appname]-[cluster] 的命名, 比较一目了然, 对于不熟悉 Kubernetes PV 那一套的同事而言, 做事情也更加方便一些.
妙用: 网盘
有了一个随心所欲存文件的地方, 自然而然的念头就是如何方便地把文件分享出去. 大家都知道 jfs 是可以在各个平台挂载的 (甚至 Windows 上也很好用了), 但这并不是我要介绍的, 因为让用户各自在本地挂载 jfs, 操作难度很大(何况还有安全问题). 我的意思是你可以简单搭建一个 web 服务, 挂载 jfs, 然后将文件暴露出下载入口.
做这件事真的特别简单, 我当时从萌生想法到搭建完毕不过 5 分钟, 多亏了 lain, 只需要这样一份简短的 values.yaml, 就能用 Python 拉起来 http.server:
appname: jfs-http-server
volumes:
- name: jfs-data
hostPath:
path: "/jfs"
type: Directory
volumeMounts:
- name: jfs-data
mountPath: /jfs
deployments:
web:
replicaCount: 1
image: python:latest
podSecurityContext: {}
resources:
limits:
cpu: 1000m
memory: 80M
requests:
cpu: 10m
memory: 80M
command: ["python", '-m', 'http.server']
workingDir: /jfs
containerPort: 8000
ingresses:
- host: jfs
deployName: web
paths:
- /
稍有开发经验的人就能看明白, 这是用社区的 python:latest 镜像, 运行 http.server, 然后挂载了宿主机的 /jfs 目录. 服务上线以后, 访问 jfs.example.com 就能浏览和下载 jfs 下的所有文件了.
相比 jfs, 这一节似乎更是在给 lain 做广告, 不过在 DevOps 的世界里, 好用的东西总会互相吸引, 如果各位的团队也实行 DevOps, 欢迎参考 lain.
妙用: 在 JupyterLab 进行 ad hoc 编程
我们团队经常要和数据打交道, 不仅是做数据报表, 可视化分析, 有时也希望在能摸到数据的地方验证一些开发思路. 总不能让大家都本地连接线上数据库吧, 既不方便也不安全, 大伙也不一定都擅长在本地折腾这方面的工具. 因此我部署了 JupyterLab, 在里边做了大量易用性改善, 也就是内置了很多公司内部数据库的快捷方式, 让所有开发者/数据工程师都能便捷地使用封装好的 Python 库来做数据分析, 甚至直接利用 bokeh 来交付数据可视化的工作.
显而易见, 在 Jupyter 里写的代码也是要进入版本管理的, 辛苦写的代码可千万不能丢了. 因此我直接将 JupyterLab 的工作目录设置为 jfs, 所有的 notebook 就都存放于 jfs 下了. 用 lain 部署 JupyterLab 十分简单, 下面就是用到的 values.yaml:
appname: lab
env:
SHELL: zsh
IPYTHONDIR: /lain/app
volumes:
- name: jfs
hostPath:
path: "/jfs/lab"
type: Directory
volumeMounts:
- name: jfs
mountPath: /jfs/lab
deployments:
web:
replicaCount: 1
podSecurityContext: {'runAsUser': 0}
terminationGracePeriodSeconds: 70
resources:
limits:
cpu: 2
memory: 4Gi
requests:
cpu: 100m
memory: 1Gi
command: ['jupyter', 'lab', '--allow-root', '--collaborative', '--no-browser', '--config=/lain/app/jupyter_notebook_config.py']
containerPort: 8888
workingDir: /jfs/lab/notebooks
ingresses:
- host: lab
deployName: web
paths:
- /
build:
base: lain:latest
prepare:
script:
- apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4
- echo "deb https://repo.clickhouse.tech/deb/stable/ main/" | tee /etc/apt/sources.list.d/clickhouse.list
- apt-get update
- apt-get install -y apt-transport-https ca-certificates dirmngr clickhouse-client=20.12.8.5 clickhouse-common-static=20.12.8.5
- apt-get clean
- pip3 install -r requirements.txt
script:
- pip3 install -r requirements.txt
光有 Jupyter 其实用途不大, 所以我上边提到, 要做好易用性建设, 比方说封装好各种 database client:
from os import environ
import pandas as pd
import pymysql
from IPython.core.display import display
class MySQLClient:
def __init__(self, config):
config.update({
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor,
'autocommit': True,
})
self.config = config
def use(self, db):
self.config['database'] = db
# just to make sure this db exists
return self.execute(f'use {db}')
def fetch(self, sql, *args, **kwargs):
return self.execute(sql, *args, **kwargs)
def fetchone(self, sql, *args, **kwargs):
kwargs.update({'fetchone': True})
return self.execute(sql, *args, **kwargs)
def executemany(self, sql, *args, **kwargs):
con = pymysql.connect(**self.config)
with con.cursor() as cur:
cur.executemany(sql, *args, **kwargs)
res = cur.fetchall()
con.close()
return res
def execute(self, sql, *args, **kwargs):
con = pymysql.connect(**self.config)
with con.cursor() as cur:
fetchone = kwargs.pop('fetchone', None)
as_pandas = kwargs.pop('as_pandas', None)
cur.execute(sql, *args, **kwargs)
if fetchone:
res = cur.fetchone()
else:
res = cur.fetchall()
con.close()
if as_pandas:
return pd.DataFrame(res)
return res
x = execute
def preview(self, table_name=None, n=2):
"""
# first, use a database
mysql_client.use('configcenter')
# show tables
mysql_client.preview()
# select example data from one table
mysql_client.preview('post')
# study one single column
mysql_client.preview('post.visibility')
"""
if not table_name:
return self.execute('show tables', as_pandas=True)
if '.' in table_name:
n = max([n, 20])
table_name, column_name = table_name.split('.')
part = self.execute(
f'''
SELECT DISTINCT {column_name}, count(*) AS count
FROM {table_name}
GROUP BY {column_name}
ORDER BY count DESC
LIMIT {n}
''', as_pandas=True
)
return part
part1 = self.execute(f'''
SELECT `column_name`,
`column_type`,
`column_comment`
FROM `information_schema`.`COLUMNS`
WHERE `table_name` = "{table_name}"
''', as_pandas=True)
display(part1)
part2 = self.execute(
f'''
SELECT *
FROM {table_name}
ORDER BY RAND()
LIMIT {n}
''', as_pandas=True
)
return part2
MYSQL_CONFIG = jalo(environ['MYSQL_CONFIG'])
mysql_client = mysql = my = MySQLClient(MYSQL_CONFIG)
mysql_client.use('mydatabase')
经过了这么一堆封装, 有多好用你都不敢想:
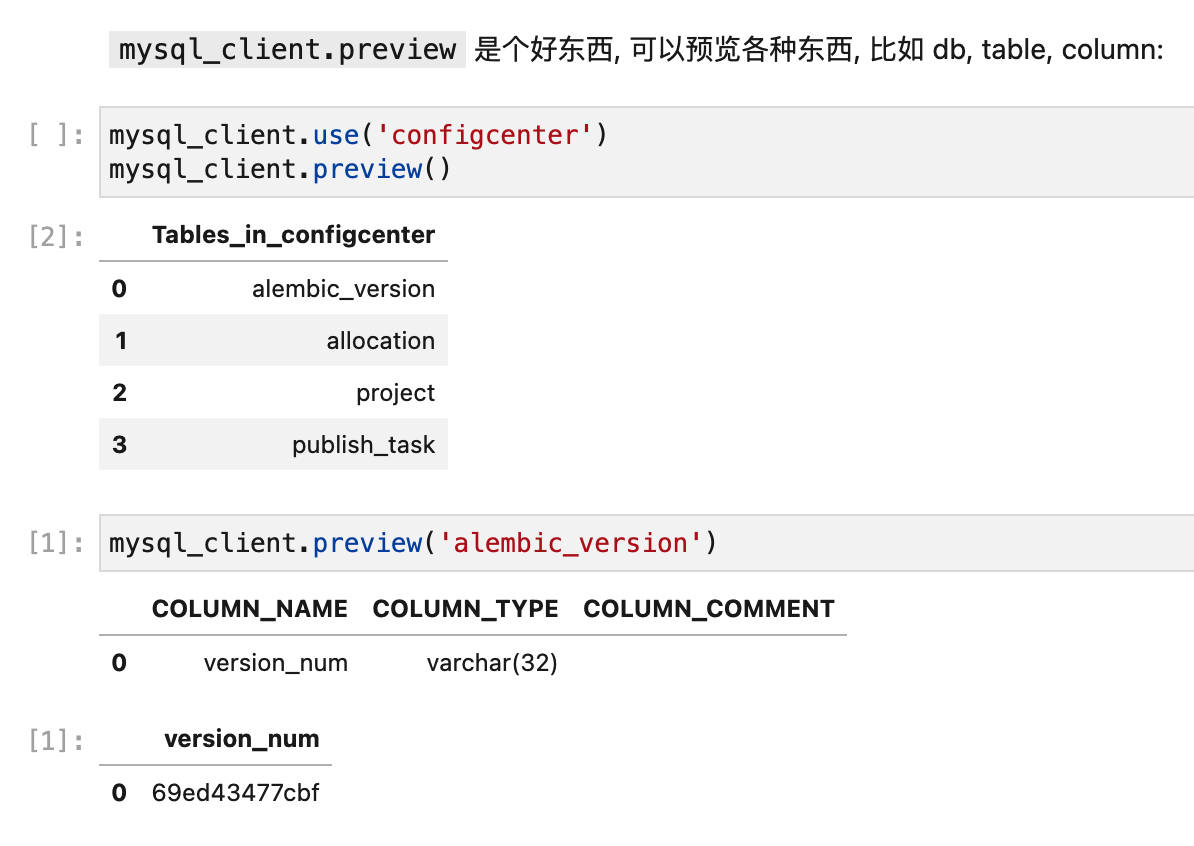
就靠着类似的快捷调用, 在我任职过的团队里, 从后端工程师, 数据分析师, 乃至于产品经理, 都能直接用 JupyterLab 进行工作.
好像主要都在介绍 Jupyter 了, 挺不好意思的. 但实际上这个项目和 jfs 关系也很紧密:
- 产生的数据报表, 或者别的 ad hoc 流程的产物, 都放在 jfs 上, 直接就能方便地分享给他人(见上方”网盘”一节)
- 所有的代码(在 Jupyter 的世界里, 叫 notebook) 都存放在 jfs, 用
juicefs snapshot来做定期备份
妙用: GitLab, ClickHouse, Elasticsearch, etc.
理论上, 所有应用需要数据落盘的时候, 你都可以放到 jfs 里, 只要合适的性能区间匹配就行. 在这一节里介绍一下我们探索过的一些用法:
- GitLab 对磁盘 IO 的要求还是挺高的, 尤其 MR 的时候, 如果代码库很大, 最好还是视情况迁到 SSD. 但如果你是个小团队, 项目不多也不大, 那放在 jfs 上就能享受到一系列额外的好处, 比如用
juicefs grep全局搜索代码仓库(找垃圾代码), 方便地用juicefs snapshot全量备份所有 repo data, 等等 - 我用 ClickHouse 配合 JuiceFS CSI, 方便地拉起 CH 集群, 这点在 小团队如何维护 Sentry 有更详细介绍, 不重复
妙用: CI
就以 GitLab CI 为例吧, 给 Runner 设置好挂载目录:
[runners.docker]
volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/jfs:/jfs:rw", "/cache"]
没想到仅仅是把 jfs 挂载到 CI Runner 里, 能打开这么多可能性, 下边的这些案例每一个都没有多”神”, 但都是因为有了 jfs, 事情变得特别方便和易维护:
发布构建产物 (Artifacts)
本来 jfs 就是用来存文件的, 将构建产物(比方说安卓打包)扔到 jfs, 再配合上文”网盘”一节介绍的文件分享, 就能轻松做出下载链接了. 如果你团队内部需要把构建产物发布给非技术人员, jfs + Python http.server 会是一个很好的配合.
持续部署
不是所有服务上线, 都是要更新容器的, 比方说不少前端应用的更新, 其实只是打包发布静态文件, 而这一步往往也是在 CI 里完成的, 这样一来, 前端应用的发布和 jfs 就能做一个很好的配合:
- CI Job 将前端应用的静态文件编译好, 发布到 jfs 下带有版本号的路径
- 更新 Nginx 配置, 将网站指向最新版的路径, 这样就算发布出去了, 需要的话还可以触发一下 CDN 预热
- 如果要回滚的话, 也可以戳一下对应版本的 CI Job, 旧版就又部署回去了
又比方说, 我们有一些项目是放到特定的服务器上运行的, 这些服务器或许在机房, 或许在办公室, 我当然可以给这些机器都做好公司内网 VPN, 然后挨个地配置出定期 git clone 更新, 但有了 jfs, 谁还用这种费力的方式来交换数据呢? 于是我们是这样做的:
- 所有服务器都挂载了 jfs, 我们的机器初始化流程里就做好了
- 项目代码随着 CI 发布到 jfs, 比方说每次更新代码, 都会对
/jfs/[appname]下的内容做覆盖 - 服务器上监听
/jfs/[appname]的文件变动, 或者做出每天深夜定时重启之类的, 都方便
全局缓存
GitLab CI, 或者别的各类 CI 系统, 都有各式各样的缓存机制吧, 但有些 CI 工具可以直接做成 Global, 而不需要 Per Project, 这种时候就直接拿 JuiceFS 存一份就好, 比方说:
Trivy
我们用 Trivy 来做容器镜像安全扫描, Trivy 需要的就是各类安全漏洞的特征数据, 扫谁都用的同一个 db, 因此我做了个 CI Job, 定期往 jfs 下更新数据:
refresh_trivy_db:
stage: schedule
variables:
TRIVY_CACHE_DIR: /jfs/trivycache
rules:
- if: '$CI_PIPELINE_SOURCE == "schedule"'
script:
- trivy --cache-dir $TRIVY_CACHE_DIR image --download-db-only
然后所有项目都可以共用这一份 jfs 下的数据, 来进行镜像漏扫了, 还不错吧:
container_scanning:
stage: release
rules:
- if: '$CI_PIPELINE_SOURCE != "schedule"'
variables:
GIT_STRATEGY: none
TRIVY_CACHE_DIR: /jfs/trivycache
script:
- trivy --cache-dir $TRIVY_CACHE_DIR image --skip-db-update=true --exit-code 0 --no-progress --severity HIGH "${IMAGE}:latest"
- trivy --cache-dir $TRIVY_CACHE_DIR image --skip-db-update=true --exit-code 1 --severity CRITICAL --no-progress "${IMAGE}:latest"
Semgrep
Trivy 是扫镜像, Semgrep 则是扫代码的, 需要定期更新用于扫描的规则文件. 通常的姿势是现场下载规则文件, 不过由于网络问题, 国内大概更愿意预先下载好这些文件, 然后直接引用. 所以轮到 jfs 出场了:
# ref: https://semgrep.dev/docs/semgrep-ci/sample-ci-configs/#gitlab-ci
semgrep:
image: semgrep-agent:v1
script:
- semgrep-agent
variables:
SEMGREP_RULES: >- # more at semgrep.dev/explore
/jfs/semgrep/security-audit.yaml
/jfs/semgrep/secrets.yaml
/jfs/semgrep/ci.yaml
/jfs/semgrep/python.yaml
/jfs/semgrep/bandit.yaml
rules:
- if: $CI_MERGE_REQUEST_IID
至于更新规则文件的流程, 没啥难度, 所以这里就不赘述了.