lain - A DevOps Solution
往高了说, lain 是一个 DevOps 方案. 但其实, lain 只是帮你封装了 helm, docker 和 kubectl, 让开发者更便捷地管理自己的 Kubernetes 应用.
在 EIN 后期 (19 年末), 我的主要工作就是基于 Kubernetes / Helm 来重写内部的云平台方案(那会恰逢 Helm 3.0 发布, 真的天助). 不过说实话, 也不能称之为重写, 因为 lain2 是一个基于 Docker 自研的云平台, 而我的重做仅仅是包装 Kubernetes / Helm, 是彻头彻尾的工程效率上的事情, 非常之低技术.
虽然是低技术, 但也算是工作至今自己最为自豪的项目, 不仅工程质量令我较为满意, 而且还实实在在帮助到了团队. 到现在, lain 经历了三家公司的孵化, 已经是具有一定成熟度的项目了. 因此近期, lain 的开发转移到了开源空间, 也趁热写点介绍性的文字, 让有需要的熟人同事们参考下.
和 Kubernetes 打交道, 需要书写成百上千行的 YAML (也就是 Kubernetes Manifests), 然后喂进去. 这堆 YAML 管理起来实在困难, 所以才产生了 Helm: Helm 可以将 k8s 的配置进行模板化, 把各种大伙看不懂的资源文件都扔到 templates, 最后暴露出一份 values.yaml, 让开发者仅需填写自己关心的配置, 比方说启动命令, CPU / Memory, 等等.
但是, 大量业务开发并不熟悉 Kubernetes, 没办法自行创建 Helm Templates, 因此让他们直接使用 Helm 来上线, 对企业来说并不现实. 那么为了让整个团队都无障碍地用管理自己的应用, lain 就是用 Python 做了个 CLI, 对 helm / docker / kubectl 做了易用性封装, 即使你完全不懂 Kubernetes, lain 也能帮你快速部署上线.
设计要点和卖点
- 代码简明易懂, 可谓 dead simple. 只要你会写 Python, 就能加入到 lain 的建设中来. 不过虽说如此, 代码质量(封装抽象, 开发文档, type hint, etc.)肯定没办法和大型开源项目比
- 卓越的易用性, lain 尽量遵循 UNIX 的设计美学, 同时尽可能做到智能和易用. lain 希望做你的朋友, 帮你做好工作, 同时绝不给你添堵
- 说是易用, 但若你不熟悉 Kubernetes / Helm, 那么 lain 对你而言恐怕也并不简单. 因此 lain 有着全面而详尽的文档, 介绍 lain 及其背后的工具和系统. 文档里的所有内容都来自于团队同事的实际问答, 经梳理整合而成
- lain 没有 server 端, 是一个纯粹的 CLI, 采纳成本稍低. 这都是托了 Helm3 的福 (也许各位还记得, Helm2 是一个需要部署 server 端的大家伙, 维护起来比较麻烦. 3 则成为了纯粹 CLI)
- 不需要用户书写任何配置: 所有的集群配置, 都写死在
cluster_values下, 随着 Python Package 发布. 用户是靠不住的, 不要让他们来维护配置, 否则少不了额外的技术支持 - 疯狂整合各类云平台基础设施, 为 DevOps 提供强大的周边功能. 比如:
lain lint会结合 Prometheus 的监控数据, 为应用提供靠谱的资源声明建议lain logs --kibana会直接在浏览器打开 Kibana, 阅读该应用的日志流lain status -s会打印出 Grafana 链接, 阅读该应用的监控细节lain assign-mr会调用 GitLab API, 为 MR 分配 Reviewer. 这个和 DevOps 关系不是特别大, 只是顺手做一下, 代表 lain 可以和 SCM 打交道- 等等等等……无穷无尽的可能性! 你能想到的有意义整合, lain 都可以做
- 用 E2E 测试保证关键流程的正确性, lain 绝不会犯灾难性错误
- 持续维护, lain 诞生于初创企业, 目前有两家公司全量使用 lain 作为 DevOps 方案, 一直在积极维护
那么我们顺着 DevOps 的工作流, 简单讲讲 lain 如何在每一个环节帮助你上线:
立项: lain init
lain 内置了一份 helm chart, 所以就不用你费力书写了. 这份默认的 helm template 通用性非常好, 支持 deploy, cronjobs, statefulSet 等 Kubernetes 部署方式. 常见技术栈的前后端应用都能轻易接入.
在项目根目录下运行 lain init, 就会生成 chart 目录, 而 chart/values.yaml 就是你需要填写的”说明书”, 里边都是一些需要应用开发者填写的配置, 比如 command, resources, 以及域名相关的 ingresses. 里边有丰富的注释和文档引用, 尽可能地指导开发者正确书写配置.
假设我们面对的集群叫 test 吧. 敲下 lain use test, 就会将本地的 ~/.kube/kubeconfig-test 软链到 ~/.kube/config. 至于 kubeconfig 文件是怎么来的呢? 咱们就先别管了. 你团队如果真的要启用 lain 的话, SA 会做好配置文件的分发, 本文只是最简单的演示.
构建镜像: lain build
要上线到 k8s, 肯定需要先构建出容器镜像. 我们以 dummy 为例, 在 values.yaml 里书写如下内容, 作为示范:
build:
base: python:latest
script:
- pip3 install -r requirements.txt
写完保存, 运行 lain build --push, 你就能看到 lain 开始调用 docker 做事情了. 这个构建过程就是以 python:latest 作为基础镜像, 然后安装 Flask, 特别简单. dummy 是一个傻瓜 Flask APP, 只需要 Python 运行环境, 有 Flask, 就能轻松跑起来.
构建完毕以后, 如果你有兴趣, 还可以用 lain run 来本地调试镜像, 看看构建产物是不是符合你的预期. lain build 还有不少方便好用的功能, 比如反复构建镜像的时候, 我们总是嫌耗时长, 吃资源, 这时候可以用 build.prepare 做出缓存中间层, 存放不怎么变动的大块头依赖, 避免每次构建都重复安装.
环境变量 / 配置文件管理
lain 提供灵活的 env 管理手段. 首先, 你可以在 values.env 里书写环境变量, 而如果你要添加的 env 属敏感信息, 不宜存放在代码仓库里, 这种情况可以用 lain env 管理, 这个命令是 lain 对 Kubernetes Secret 做的易用性封装, 你可以用 lain env [add|edit] 来添加或编辑环境变量.
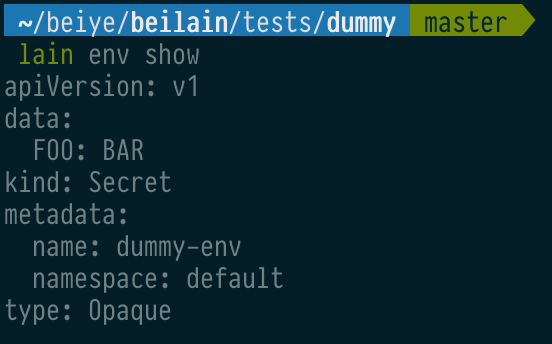
除了 lain env, 我们还有 lain secret, 用于管理配置文件, 一样用 lain secret [add|edit] 就能添加和编辑:
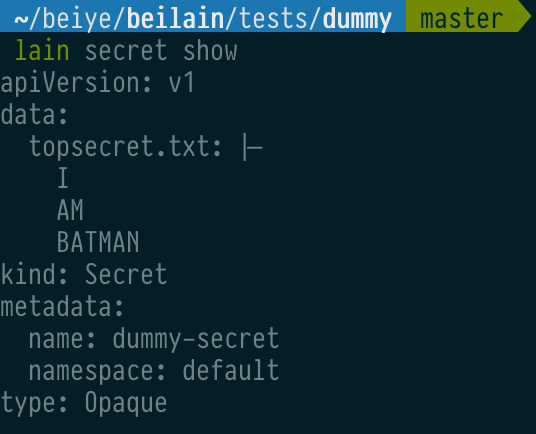
配置文件的挂载也很简单, 当你添加上传好配置文件以后, 在 values.yaml 里写这么一小块配置即可:
volumeMounts:
# topsecret.txt 就是上方我们添加的"机密配置文件"
- subPath: topsecret.txt
# mountPath 则用来控制, 该文件/目录要挂载到容器内的什么路径
mountPath: /lain/app/deploy/topsecret.txt
上线: lain deploy
没花多长时间, 我们就有了 helm chart, 还有了镜像, 那确实接下来就可以上线了. 写一下 web server 的启动命令, 和对应的域名配置:
deployments:
web:
replicaCount: 1
resources:
limits:
cpu: 1000m
memory: 80Mi
requests:
cpu: 10m
memory: 80Mi
command: ["/lain/app/run.py"]
containerPort: 5000
# ingresses 用来声明内网域名
ingresses:
- host: dummy
deployName: web
paths:
- /
这一小块配置就能告诉 Helm / Kubernetes, 应该如何启动你的应用, 启动几个实例(容器), 分配多少资源.
敲下 lain deploy, 就能看见 lain 结合集群配置, 以及应用配置, 调用 helm 来操作上线:
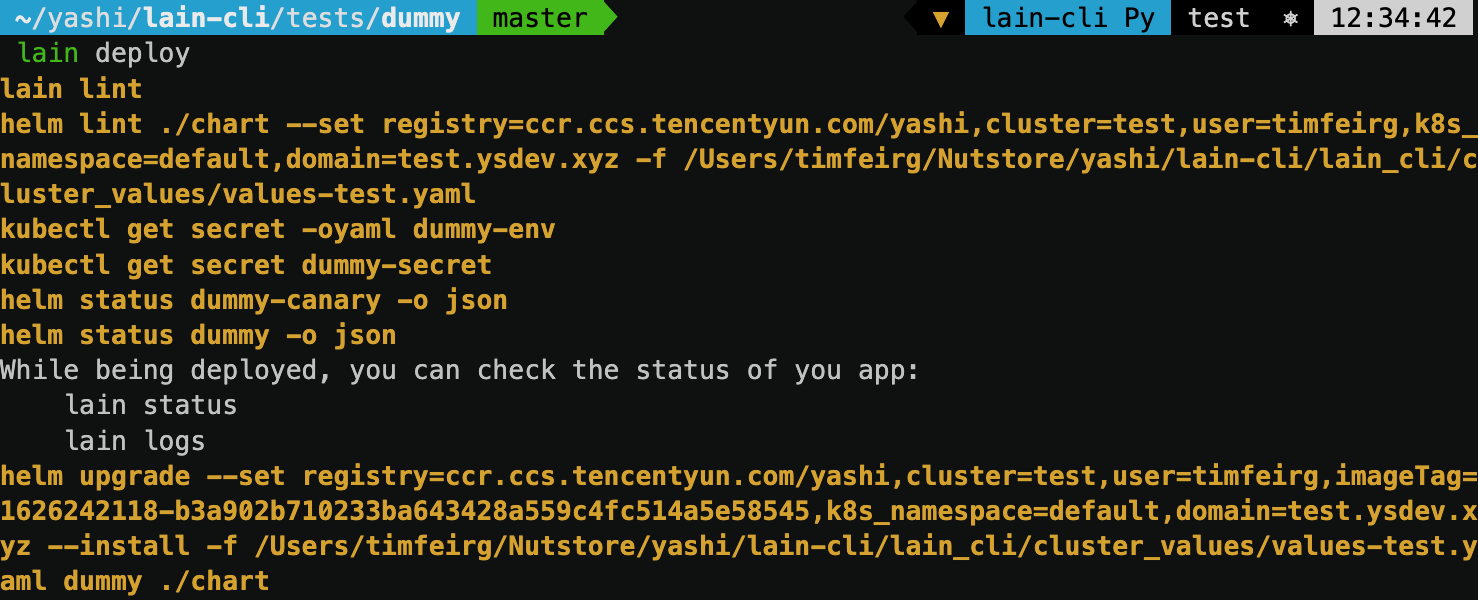
lain 喜欢把三方调用的命令都以黄字打印出来, 让你清楚了解其中都做了哪些事情的同时, 也方便错误排查.
验证服务
部署上去以后, 开发者最关心几个要素: 容器健在吗? 占用资源情况? 有无报错日志? 域名是否能正常访问?
lain 深知后端工程师的这一系列日常操作流程, 因此将这些信息聚合在一处, 用 lain status 开启状态面板, 就能看到上线以后最关心的一系列信息.
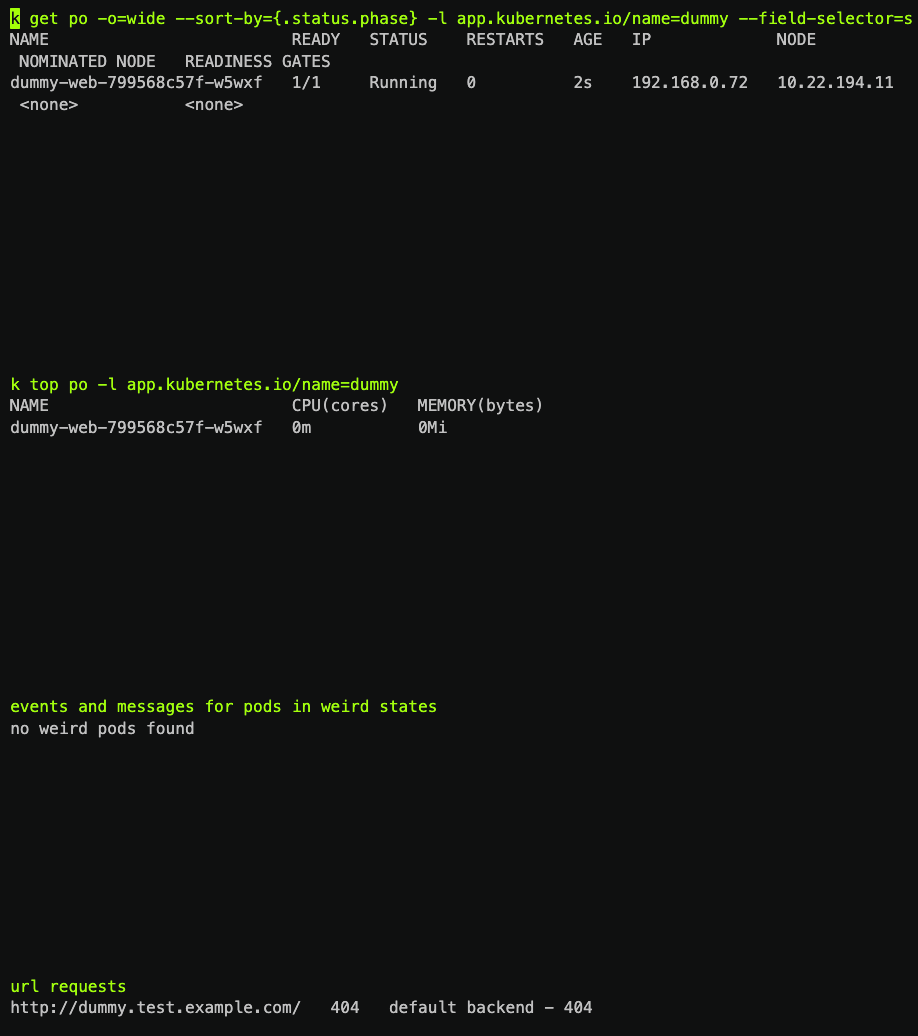
在 lain 之前, 我用过的云平台都有一个网页端, 在浏览器页面里汇聚了这些信息. 而 lain 并没有 server 端, 也就拿不出漂亮的网页了. 但以我自己的后端开发经历而言, 基于命令行的工作流往往更为高效和灵活, 也希望你们能喜欢这个设计.
不过说到底, lain status 也只是给出一个让人肉眼看绿灯的地方, 你若想在自动化上继续深耕, 可以给自己的应用撰写 values.tests, 用恰当的测试来保证上线成功 (不成功的话便报错, 发送告警之类的), 避免每次上线都要人工盯梢.
除此之外, lain 还整合了很多功能, 帮助开发者做运行时调优:
lain lint能通过 Prometheus 监控数据, 计算资源用量的 P95, 如果发现开发者书写的资源声明浪费太大, 会报错阻止开发者上线(不许浪费粮食, 或者过分超售资源)! 报错的同时, 还会打印出靠谱的资源声明建议. 很多开发者并不清楚自己的应用到底是个什么资源开销, 这个命令是很好的兜底.lain status -s不仅打印出当前的应用状态, 还列举了 Grafana, Kibana 的链接, 点进去便能查看应用的监控和日志. 当然啦, 这些功能都需要基础设施就位, 然后在 lain 的集群配置里做好整合.
错误排查
绿灯了还好, 如果出错了该咋整?
- 除了上边提到的
lain status, 你还可以用lain logs来打印容器日志, 如果集群配置里整合了 Kibana, 你甚至可以lain logs --kibana直接在 Kibana 中阅读日志流 - 如果容器还在运行, 可以用
lain x钻进容器里进行调试 - 你也可以尝试在本地用
lain run来调试容器镜像, 看看是不是构建过程出了差错
与 CI 协同工作
DevOps 最喜欢 CI 了, 因此 lain 也围绕 CI 做了非常多事情, 用 CI 帮忙构建上线, 那都是稀松平常的标准操作了. 就不在此特意介绍.
不过近期实现的一个小脑洞就是, lain --remote-docker 会利用 CI 机器上的 docker daemon 来进行远端构建, 既节省本地资源, 也充分利用上了 CI 机器上的大量镜像缓存, 帮大家解决了笔记本电脑构建慢/硬盘不足的问题.
其余的 CI 相关的内容, 在文档里有专门罗列, 不在此赘述.