拿什么拯救 OOM
做后端开发的朋友们, 一定少不了和 OOM 打交道. 本文将会对 OOM 做一番极其浅显的介绍, 并且分享我们是如何在 Kubernetes 下做管理和监控, 来避免 OOM 的. 本文真的没多少原理介绍, 因为我自己也不怎么深入研究, 主要关注 SA 和应用开发者的各自最佳实践.
OOM 的本意是 Out Of Memory, 硬要说的话, 如果一台健康运行, 但是充分压榨资源的宿主机, 完全有可能持续处于几乎没有空闲内存的状态, 此种情况不在本文讨论之列. 本文中 OOM 一定是指系统或应用的异常情况, 也就是发生了 OOM Kill
在 Kubernetes 下跑业务, 根据容器状态是否受影响这一点, 可以将 OOM 分为两种. 一种是 Kubernetes 知道的 (在 kubectl get events 能查看 OOM Kill 日志), 一种是 Kernel 直接杀进程 (kill -9), Kubernetes 浑然不知, 容器得以继续运行. 下面以 dummy 为例, 对这两种情况进行示范:
Pod OOMKilled
这是最简明易懂的情况, 就是内存超了, 比如下方的这个垃圾程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#!/usr/bin/env python3
from time import sleep
def oom():
dic = {}
i = 1
while True:
dic[i] = i + 1
i += 1
bag = set(str(int(i)))
if bag == {'1', '0'}:
print(i)
sleep(0.5)
if __name__ == "__main__":
oom()
这个垃圾程序按照下方的设置, 给予了非常低的内存边界, 但并不超售内存, 然后用 lain 部署上线:
1
2
3
4
5
6
7
8
9
10
11
deployments:
oom:
replicaCount: 1
resources:
limits:
cpu: 100m
memory: 8Mi
requests:
cpu: 10m
memory: 8Mi
command: ["/lain/app/oom.py"]
上线以后, 用不了多久, 你就能看到尸体了:
1
2
3
$ k get pod -owide --sort-by={.status.phase} -lapp.kubernetes.io/name=dummy
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dummy-oom-6959656748-5pk5z 0/1 OOMKilled 0 16s 172.20.1.38 cluster00247dev <none> <none>
很好理解吧, 你的应用内存持续上涨, 超过了所在 cgroup 的 8Mi memory limit, 因此被 Kubernetes 干掉了, 并且将你的容器状态记为 “OOMKilled”. 只要容器的内存占用超过了 cgroup memory limit, 就会是这个结果.
静默 OOM
为了方便起见, 下文用”静默 OOM” 来指代”容器子进程被 OOM Kill, 容器本身却仍 Running” 的情况.
这是更加棘手的 OOM 情况, 我们都不愿意看见. 事实上, 如果不去对 /var/log/messages 做监控, 我们想看也看不见, 只能静候业务异常. 这种情况常见于主进程是 daemon 的容器应用, 比如 Celery, PM2. 示范如下:
上方的 Python OOM 垃圾脚本, 包装成一个 Celery APP:
1
2
3
4
5
6
7
from celery import Celery
from oom import oom
app = Celery('tasks', broker='redis://redis-master')
oom = app.task(oom)
oom.delay()
然后用下方的配置进行 lain deploy:
1
2
3
4
5
6
7
8
9
10
11
deployments:
celery:
replicaCount: 1
resources:
limits:
cpu: 100m
memory: 800Mi
requests:
cpu: 10m
memory: 80Mi
command: ["celery", "-A", "tasks", "worker", "--loglevel=DEBUG"]
上线以后, 如果情况合适, 那么运行许久, 发现容器都是建在的, 并未转为 OOMKilled 或者重启:
1
2
3
$ k get pod -owide --sort-by={.status.phase} -lapp.kubernetes.io/name=dummy
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dummy-celery-5c78b978d-5gvmd 1/1 Running 0 20m 172.20.1.24 cluster00247dev <none> <none>
但是一看日志, 发现其实内部已经 Worker Lost:
1
2
3
4
5
6
7
$ k logs -f dummy-celery-5c78b978d-5gvmd
[2022-04-01 16:03:10,221: ERROR/MainProcess] Process 'ForkPoolWorker-6' pid:13 exited with 'signal 9 (SIGKILL)'
[2022-04-01 16:03:10,239: ERROR/MainProcess] Task handler raised error: WorkerLostError('Worker exited prematurely: signal 9 (SIGKILL) Job: 0.')
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/billiard/pool.py", line 1265, in mark_as_worker_lost
raise WorkerLostError(
billiard.exceptions.WorkerLostError: Worker exited prematurely: signal 9 (SIGKILL) Job: 0.
跑到容器所在的节点上看 /var/log/messages, 找到了对应的日志:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
kernel: celery invoked oom-killer: gfp_mask=0x6200ca(GFP_HIGHUSER_MOVABLE), nodemask=(null), order=0, oom_score_adj=998
kernel: celery cpuset=cri-containerd-ff9bfe96b7ecf8cf9952b7db762ebf66a0766692dea902267588b81785ae1383.scope mems_allowed=0
kernel: CPU: 3 PID: 1540678 Comm: celery Kdump: loaded Not tainted 4.19.91-25.6.al7.x86_64 #1
kernel: Hardware name: Alibaba Cloud Alibaba Cloud ECS, BIOS 90210cb 04/01/2014
kernel: Call Trace:
kernel: dump_stack+0x66/0x8b
kernel: dump_memcg_header+0x12/0x40
kernel: oom_kill_process+0x219/0x310
kernel: out_of_memory+0xf7/0x4f0
kernel: mem_cgroup_out_of_memory+0xc2/0xe0
kernel: try_charge+0x7b4/0x810
kernel: ? blk_finish_plug+0x27/0x40
kernel: ? read_pages+0x6b/0x180
kernel: mem_cgroup_charge+0xfe/0x250
kernel: __add_to_page_cache_locked+0x68/0x2c0
kernel: ? __radix_tree_lookup+0x70/0xd0
kernel: add_to_page_cache_lru+0x39/0xb0
kernel: pagecache_get_page+0xba/0x370
kernel: filemap_fault+0x38d/0x700
kernel: ext4_filemap_fault+0x2c/0x3b
kernel: __do_fault+0x38/0x170
kernel: do_fault+0x398/0x880
kernel: __handle_mm_fault+0x5bc/0xaa0
kernel: handle_mm_fault+0x10d/0x200
kernel: __do_page_fault+0x1c3/0x4e0
kernel: do_page_fault+0x32/0x140
kernel: ? async_page_fault+0x8/0x30
kernel: async_page_fault+0x1e/0x30
kernel: RIP: 0033:0x7fe2f8093ad1
kernel: Code: Bad RIP value.
就是这么个情况, 容器虽然看上去是建在, 但其实子进程已经被杀, 业务不能稳定运行. 再加上 Celery 会重新启动 Worker, 所以表面上看起来甚至会自愈, 让人卸下警惕, 忘了深入排查.
不过上边的情况也不是按照流程部署, 就一定能复现的, 为了确保观察到静默 OOM, 建议你选一台内存吃紧, 并且超售比较严重的机器来部署, 因为静默 OOM 是这样发生的:
- 容器本身资源设置就做了内存超售 (memory limits 大于 memory requests, 并且通常是远大于)
- 容器实际占用的内存大于 memory requests, 低于 memory limits, 也正是因为低于 memory limits, 所以没有直接被 Kubernetes 杀掉
- Kubernetes 虽然未做干预, 可是宿主机内存冗余不足, 所以虽然容器的内存占用并未触及 limits, 但由于持续上涨, 摸到了系统资源边界, 因此 OOM Killer 出手杀人了
- Kernel OOM Killer 杀的是容器子进程, 以上方为例, 杀的其实是 Celery Worker
严丝合缝的监控
对于 Pod OOMKilled 的情况, 监控还是很好做的, 有 Prometheus 就行, 例如:
1
2
3
4
5
6
7
8
9
10
11
alerting_rules.yml:
groups:
- name: kubernetes
rules:
- alert: PodOOMKilled
expr: sum(kube_pod_container_status_terminated_reason{reason="OOMKilled"}) by (pod) > 0
for: 1m
labels:
severity: warning
annotations:
summary: "increase memory limit for this app, RIGHT NOW! (see lain lint for suggestions)"
而对于静默 OOM, 只要将系统日志监控起来, 也是一样能做告警的. 我们用 grok-exporter 来做:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
global:
config_version: 2
input:
type: file
path: /var/log/messages
grok:
patterns_dir: "/etc/grok_exporter/patterns"
metrics:
- type: counter
name: oom_counter
help: Count kernel oom events
# 日志格式请按照现场采集为准, 不同版本的 Kernel, OOM Kill 的日志也许不一样
match: '%{HOSTNAME:nodename} kernel:%{GREEDYDATA}Killed'
labels:
nodename: '{{.nodename}}'
server:
port:
将 grok-exporter 部署在所有 Kubernetes Worker, 然后搭配 Prometheus 的告警规则:
1
2
3
4
5
6
7
8
9
10
11
alerting_rules.yml:
groups:
- name: node-rule
rules:
- alert: RecentOOM
expr: changes(oom_counter[10m]) > 5
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $value }} OOM events on instance in the last 20 minutes, checkout out {{ $labels.nodename }}:/var/log/messages"
这样一来, 集群里所有的 OOM Kill 都逃不过法眼, 不用再提心吊胆怕静默 OOM, 也不用费力看容器日志和系统日志, 来追查 OOM, 一切尽在掌控中.
防患于未然
做好了监控确实令人安心, 但这还不够. 如果你不好好规范应用资源声明, 规划集群冗余, 监控做再好, 你也要面临打地鼠的情况: 今天这个应用 OOM, 明天那个应用浪费内存, 逼得其他人 OOM. 因此在这里介绍我们研发和 SA 团队在 DevOps 下作的一些相关安排.
后端研发
所有应用都要做到, 对内存没有明显的浪费, 什么叫明显的浪费? 比方说应用声明了 3Gi memory requests, 可实际上常年只用 1Gi, 相当于 Kubernetes 给容器做了 3Gi 的 cgroup, 其中 2Gi 都是闲置, 是极大的浪费, 如果放在在一个普遍超售的环境下, 也会明显给其他应用增加 OOM 风险.
这件事只能放到平台来做, 比方说 lain 整合了 Prometheus, 可以直接在 lain deploy 的时候做检查, 如果应用的资源声明不合规, 就直接打断报错, 建议整改.
不过说到底, 检查资源声明只能作为一个软性措施, 因为平台是服务研发大哥的, 是”太监”, 归根结底只有业务才最了解业务研发, 了解应用到底需要多少内存. 业务大哥说, “我这个应用虽然现在浪费内存, 可是之后就会蹭蹭涨起来了, 你可别瞎指挥, 我说要 3Gi, 那就必须 3Gi”, 这也是合理的诉求, 因此平台层面也要做一些事情, 才能共同做好防范.
平台层面
- 生产集群永远保证起码(比方说) 30% 的内存冗余, 设立定期巡查或者告警都可以. 开发集群就随便了, 反而应该尽量压榨机器
- 在监控系统里对各个应用的内存超售, 以及内存浪费情况做汇总排序, 做成监控看板, 这样一来谁浪费严重, 谁风险大, 一目了然
- 等集群资源吃紧, 需要扩容或者腾资源的时候, 首先去”挑战大头”, 也就是挑出最占用资源的一系列应用, 去质问业务研发能否以优化内存占用. 如果不优化, 那就需要”老板”知会, 亮绿灯. 应用才是大爷, 想吃多少吃多少, 老板同意就行
上边提到的内存超售和监控看板, 在 Prometheus / Grafana 下, 做出来的监控图大概长这样:
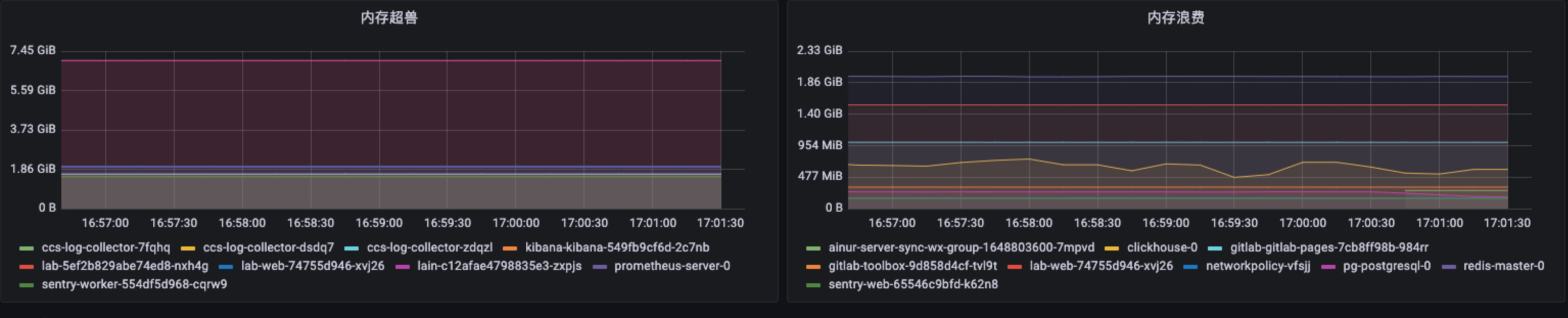
做出这个 Grafana 看板所需的 PromQL 也贴一下, 供参考:
1
2
3
4
5
6
7
8
9
10
11
12
# 内存超售
sum by (pod) (kube_pod_container_resource_limits{resource="memory"} - kube_pod_container_resource_requests{resource="memory"}) > 2900000000
# 内存浪费
sum by (pod) (kube_pod_container_resource_requests{resource="memory"})
-
sum(
label_replace(
container_memory_usage_bytes{container!="sandbox"}-container_memory_cache{container!="sandbox"},
"pod","$1","container_label_io_kubernetes_pod_name","(.+)"
) ) by (pod)
> 290000000
上方的 PQL 里, 每一句末尾都有个阈值, 这个数字需要根据每个集群的情况自行调整, 只把超售或浪费最严重的十个容器展示出来就好, 否则所有 Pod 都会显示在看板上, 性能会撑不住.